Types of Machine Learning Models and When to Use Them
May 22, 2025
We hear a lot about Artificial Intelligence (AI) these days, but what’s really powering those smart systems? It’s Machine Learning (ML). a field of AI that lets computers learn from data and improve over time. It all depends on the Machine Learning Models you use. These models are the brain behind the operation, spotting patterns, making predictions, and helping systems get smarter every day.
According to recent report, Machine learning models power 80% of enterprise AI solutions, driving a $209 billion market by 2025. From classification models detecting fraud to regression models forecasting sales, understanding ML’s backbone is critical.
This blog post will provide a comprehensive overview of various Machine Learning Models, their underlying principles, and practical guidance on Choosing the right machine learning model for your data for diverse applications, and decodes the different types of machine learning models, when to use them, and how they can be implemented in real-world applications.
What is Machine Learning?
At its core, Machine Learning is a branch of Artificial Intelligence (AI) that empowers systems to learn from data, identify patterns, and make decisions or predictions, without being explicitly programmed. It’s what enables apps to recommend your next favorite song, or fraud systems to flag unusual transactions in real time.
This technology fuels everything from voice assistants to advanced data analytics, and it’s shaping the future of automation and intelligence in every industry.
Key Concepts of Machine Learning Models
At the heart of any machine learning model lies data. These models are trained using massive datasets, which they process to learn patterns, relationships, and structures.
Over time, the models are retrained with new data, allowing them to refine their predictions and adapt to changing conditions. This aspect is especially important when discussing the difference between supervised and unsupervised learning, where one uses labeled data and the other learns from structure without explicit instructions.
The ultimate goal? Prediction. From regression models that estimate house prices to classification models that detect spam, ML helps businesses and systems forecast future events or make real-time decisions.
Types of Machine Learning and Their Use Cases
Understanding the Types of Machine Learning is crucial when building intelligent systems. ML is not a one-size-fits-all approach, each category solves different problems, depending on the nature of the data and the intended outcome. If you’re choosing between supervised, unsupervised, or reinforcement learning, knowing when and how to apply each is key.
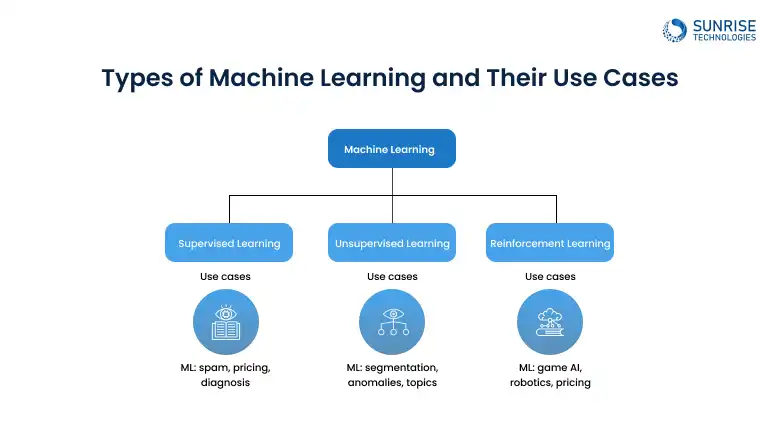
Let’s explore the three main types of machine learning with examples and their real-world applications of ML models.
In Supervised Learning, the model learns from a labeled dataset, meaning the input comes with the correct output. This is like teaching a child with flashcards; the system already knows what it’s supposed to learn. This is one of the most widely used approaches in business and healthcare, making it a go-to in the list of best machine learning models for classification.
Use cases:
- Spam classification in emails
- Predicting housing prices based on area, size, and location
- Medical diagnosis using patient data
Unlike supervised learning, Unsupervised Learning deals with unlabeled data, no predefined categories or outcomes. The model identifies structure and patterns on its own. Great for businesses exploring types of ML algorithms and their use cases in exploratory data analysis.
Use cases:
- Customer segmentation in marketing
- Anomaly detection in cybersecurity or finance
- Topic modeling in NLP
Reinforcement Learning (RL) involves an agent that learns by interacting with an environment, receiving rewards or penalties based on its actions. Think of it as training a dog using treats and discipline.
Use cases:
- Game AI like AlphaGo
- Robotic control systems
- Dynamic pricing in e-commerce
Supervised vs Unsupervised vs Reinforcement Learning – Quick Comparison
| Aspect | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data | Labeled | Unlabeled | Action-feedback loop |
| Goal | Predict outcomes | Discover hidden patterns/clusters | Maximize cumulative rewards |
| Examples | Spam detection, price prediction | Customer segmentation, anomaly detection | Game playing, self-driving, robotics |
| Algorithms | Linear Regression, SVM, Decision Trees | K-Means, PCA, Hierarchical Clustering | Q-Learning, SARSA, Deep Q-Networks |
| Feedback | Direct (with known output) | No direct feedback | Indirect via rewards/penalties |
| Training Process | One-time training with historical labeled data | Pattern discovery through data structure analysis | Continuous learning via exploration & exploitation |
| Computational Cost | Generally lower than RL | Moderate | High due to simulation or environment interaction |
| Applications | Email filtering, stock forecasting, diagnostics | Market segmentation, recommendation systems | Robotics, gaming AI, autonomous decision-making |
What is a Machine Learning Model?
At its core, a Machine Learning Model is a mathematical or computational function trained to make sense of data. Think of it as a system that learns from examples rather than being hardcoded with rules. Once trained, it can transform raw inputs into useful predictions, from classifying emails as spam to forecasting market trends.
So, if you’re choosing the best machine learning model for classification or determining when to use regression models in machine learning, understanding what an ML model is and how it learns sets the foundation for successful implementation.
- 1. Data QualityGarbage in, garbage out, models are only as good as the data they learn from. Clean, relevant, and diverse datasets lead to better generalization and accuracy.
-
2. Chosen Algorithm
- • For linear trends, use Linear Regression.
- • For image classification, go for Convolutional Neural Networks (CNNs).
- • For sequence data, Recurrent Neural Networks (RNNs) or Transformers work best.
-
3. Training Process Models learn by minimizing a loss function, this means reducing the error between predicted and actual values during training. This process involves:
- • Forward pass (prediction)
- • Loss calculation
- • Backpropagation (updating weights)
- • Iteration until convergence
Types of Predictions ML Models Make
Understanding the different types of machine learning predictions helps you align the right model with the right business or research problem.
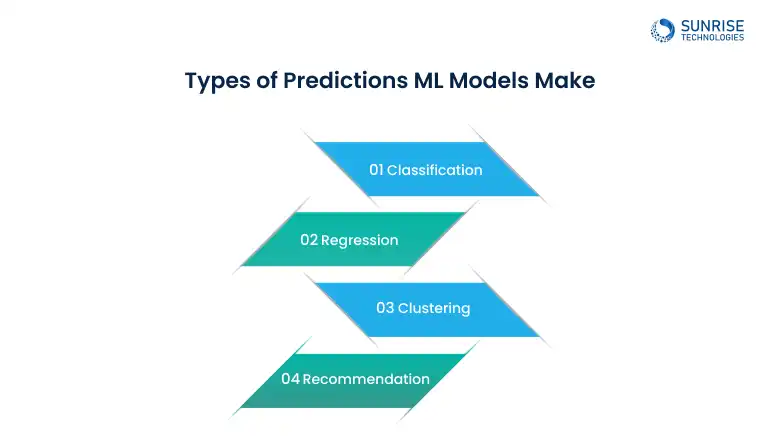
Classification Models are used when the output variable is categorical. These models learn from labeled data to predict discrete classes, such as identifying whether an email is spam or not. Popular algorithms include Logistic Regression, Random Forests, and Support Vector Machines (SVM).
Best machine learning models for classification are widely applied in fraud detection, sentiment analysis, and disease diagnosis.
Regression Models are designed to predict continuous numerical values. They analyze the relationship between input features and a target variable, such as predicting housing prices or sales revenue. Algorithms include Linear Regression, Lasso, and Gradient Boosting Regressors.
Knowing when to use regression models in machine learning is crucial in finance, economics, and supply chain forecasting.
Unlike classification, clustering is an unsupervised learning task. The model identifies natural groupings within unlabeled data. It’s widely used for customer segmentation, image compression, and anomaly detection. Algorithms like K-Means, DBSCAN, and Hierarchical Clustering are commonly used.
Recommendation systems use past behavior and similarities to predict user preferences. These models often combine collaborative filtering with content-based filtering. Netflix, Amazon, and Spotify all use such systems to improve user engagement.
Use the right ML algorithm to uncover actionable insights. Accelerate growth with data-driven decision-making.
All Types of Machine Learning Models: Exploring Algorithms and Use Cases
Machine learning (ML) is a dynamic field, and understanding types of ML algorithms is key to applying them effectively across a range of use cases. These models are primarily divided into supervised learning, unsupervised learning, and reinforcement learning categories, with each having its own strengths based on the problem you’re solving.
-
1. Linear Regression
- • Linear Regression is one of the most basic yet powerful regression models. It predicts a continuous output based on one or more input variables.
- • When to use regression models in machine learning: Whenever you're dealing with continuous outcomes that can be modeled as a linear relationship.
- • Linear Regression is a great starting point for price prediction in real estate, stock markets, and sales forecasting.
Use Case: Predicting house prices based on features like area, location, and number of rooms.
-
2. Logistic Regression
- • While it’s called regression, logistic regression is used for binary classification problems where the output variable is categorical. It estimates probabilities that a given input belongs to a particular class.
- • A foundational algorithm for classification models, especially for binary outcomes like disease presence/absence or loan approval.
Use Case: Classifying emails as spam or not spam.
-
3. Decision Trees
- • Decision Trees split data based on different criteria to make a series of decisions. It’s a flexible algorithm used for both classification and regression tasks, and its tree structure makes it easy to interpret.
- • Decision Trees are intuitive and great for applications requiring explainability, like financial forecasting and healthcare decision-making.
Use Case: Loan eligibility prediction where each decision branch reflects criteria like credit score, income, and loan amount.
-
4. Random Forest
- • Random Forest is an ensemble learning model, combining multiple decision trees to make more accurate predictions. By aggregating decisions from several trees, it reduces overfitting.
- • Random Forest offers high accuracy and versatility, making it ideal for complex real-world applications of ML models like credit card fraud detection.
Use Case: Fraud detection in banking systems, identifying anomalies across multiple features.
-
5. Naive Bayes
- • Naive Bayes is based on Bayes’ theorem and assumes that features are independent of each other. It's highly efficient for classification tasks with a large dataset.
- • Naive Bayes shines in text classification and spam filtering, making it a go-to choice for Natural Language Processing (NLP) applications.
Use Case: Sentiment analysis of social media data to classify whether customer reviews are positive, negative, or neutral.
-
6. Support Vector Machines (SVM)
- • Support Vector Machines find the best hyperplane that separates different classes in the feature space. It’s known for its ability to create a clear margin of separation between classes.
- • SVMs excel in high-dimensional spaces, commonly used in facial recognition and text classification.
Use Case: Image recognition for distinguishing between various types of objects, such as recognizing animals in photos.
-
7. K-Means Clustering
- • K-Means is one of the most popular clustering algorithms, grouping data points into K clusters based on their similarities.
- • Clustering is invaluable for market analysis and targeted advertising, making it a core tool for eCommerce and retail analytics.
Use Case: Customer segmentation where customers are grouped based on purchasing behavior or demographics.
-
8. Principal Component Analysis (PCA)
- • PCA is a powerful tool for reducing the number of features in a dataset while retaining as much variability as possible. This technique helps simplify data, making it easier to visualize and model.
- • A key tool for preprocessing and feature engineering in machine learning projects dealing with high-dimensional datasets.
Use Case: Compressing image data for storage or reducing the dimensionality of gene expression data in bioinformatics.
-
9. Q-Learning
- • Q-Learning is a type of model-free reinforcement learning algorithm where the agent learns the optimal policy to maximize the cumulative reward.
- • Q-learning is foundational for game AI, and robotics, and in dynamic decision-making environments like automated trading.
Use Case: Training an AI agent to play video games like chess or Go.
-
10. Deep Q Networks (DQN)
- • DQN is an extension of Q-Learning where deep neural networks are used to approximate the Q-values. It allows RL to be applied to more complex environments with high-dimensional state spaces, like video games.
- • Deep Q Networks are pushing the boundaries of AI, especially in autonomous systems and robotics.
Use Case: Game AI like AlphaGo, where deep Q-networks learn to play complex board games by analyzing millions of game scenarios.
Choose the Right Machine Learning Model
Choosing the right model for your problem is crucial. By carefully evaluating your data and business goals, you can select the best machine learning model that will drive success. Here’s how you can make the best choice:
- 1. Data Type: Supervised or unsupervised? The choice depends on whether you have labeled data.
- 2. Problem Type: Are you working on a classification problem, or do you need to predict continuous values (regression)?
- 3. Complexity: Some models, like decision trees, are simple and interpretable, while others, like deep Q-networks, may require substantial computational power and training time.
Let us match the algorithm to your business case. From Naive Bayes to Neural Networks, we’ve got your back.
Model Training in Machine Learning
So, how to How to train machine learning models? Model training is the core process where machine learning algorithms learn patterns from data. It’s not just about throwing data at a model, it involves several critical steps to ensure the model generalizes well and performs effectively in the real world.
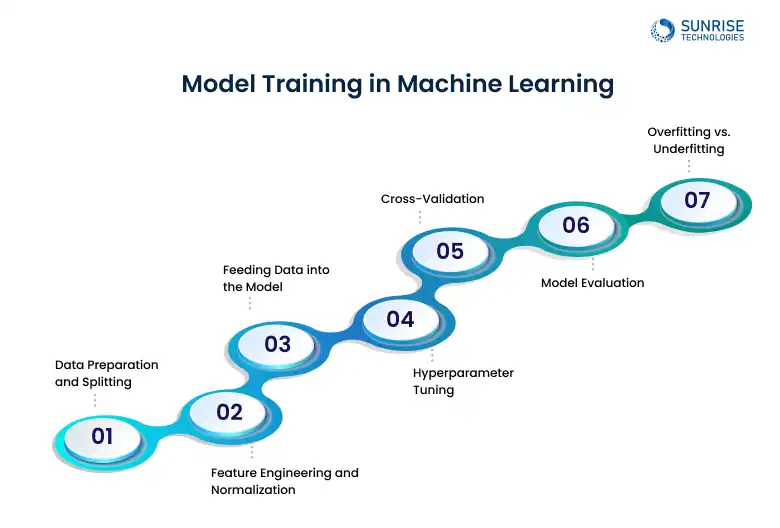
In many cases, an 80-10-10 or 70-15-15 split is used.
- Before training, the dataset is typically split into three subsets:
- Training Set: Used to train the model.
- Validation Set (optional but ideal): Used to fine-tune hyperparameters and prevent overfitting.
- Test Set: Used to evaluate final model performance.
This step ensures that the input features are compatible with the selected algorithm. Raw data often needs transformation:
- Scaling features (e.g., using Min-Max or Standard Scaler)
- Encoding categorical variables (e.g., One-Hot Encoding)
- Handling missing values (e.g., mean imputation or model-based strategies)
Once preprocessed, the training data is passed to the chosen ML algorithm:
- Gradient Descent or its variants (like Adam or RMSprop) optimize the loss function.
- The model iteratively adjusts weights to minimize the cost/loss function (e.g., MSE, Cross-Entropy).
Models have configurable settings that impact learning, known as hyperparameters. Examples: learning rate, number of trees in Random Forest, number of layers in neural networks.
Tuning Techniques:
- Grid Search: Exhaustive search over a predefined parameter grid.
- Random Search: Random combinations from the grid.
- Bayesian Optimization: Uses probability to choose the next set of parameters.
Instead of relying on one static test set, K-Fold Cross-Validation splits data into K subsets and rotates training/validation. This provides a more robust estimation of performance.
Advanced techniques like confusion matrix analysis and SHAP values help interpret predictions and model behavior. Performance is measured using different metrics depending on the problem type:
Classification:
- Accuracy
- Precision
- Recall
- F1-Score
- ROC-AUC
Regression:
- Mean Absolute Error (MAE)
- Mean Squared Error (MSE)
- R² Score
Regularization methods (L1/L2), dropout (for neural nets), and early stopping help mitigate these issues. During training:
- Overfitting: Model performs well on training data but poorly on unseen data.
- Underfitting: Model fails to capture patterns even in training data.
How to Integrate Machine Learning Models into Systems
Deploying a machine learning model is the starting point of real-world impact. Integration is where your model transitions from a Jupyter notebook into a live, scalable system that delivers predictions and value in real time. Here’s how to do it, step-by-step with a technical lens:
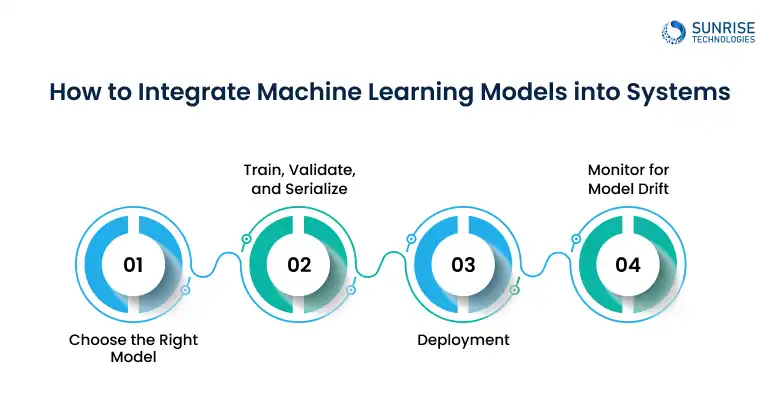
Model selection is about alignment with the data distribution, feature types, latency requirements, and deployment environment. Always benchmark different models using cross-validation and relevant performance metrics before moving to production.
- Structured/tabular data → Try decision trees, XGBoost, or logistic regression.
- High-dimensional text or images → CNNs, RNNs, or transformer-based models.
- Real-time predictions needed? → Lightweight models or ONNX-optimized versions are ideal.
Store the model artifact in a model registry (e.g., MLflow, AWS SageMaker Model Registry). After training with your best model.
- Use validation techniques like K-Fold CV to ensure robustness.
-
Serialize the model with tools like:
- joblib or pickle for Scikit-learn
- SavedModel format for TensorFlow
- TorchScript for PyTorch
Use CI/CD tools like GitHub Actions, Jenkins, or MLflow pipelines for seamless retraining and redeployment workflows. Once trained and serialized, you need a deployment mechanism:
- REST API with Flask/FastAPI – Wrap the model in an HTTP endpoint for real-time scoring.
- Containerized Microservices – Use Docker + Kubernetes for scalable model deployment.
- Cloud-native services – Deploy via AWS SageMaker, Azure ML, or Google Vertex AI.
- Edge Deployment – Convert models to TensorFlow Lite, Core ML, or ONNX for edge inference.
Once live, model performance can degrade over time due to data drift or concept drift. Tools like Prometheus + Grafana, Evidently AI, or WhyLabs can be integrated for drift detection and alerting.
Key metrics to track:
- Prediction distribution vs. training data
- Latency and throughput
- Real-time feedback loops
- Model confidence scores
Popular and Best Machine Learning Models for Real-World Applications
Choosing the best machine learning model development depends on your dataset, target outcome, performance requirements, and the problem domain. Below, we break down the most top machine learning models along with their technical strengths, ideal use cases, and when to choose them in production-level system.
Best Machine Learning Models for Classification Tasks Classification tasks involve predicting discrete labels, think spam detection, customer churn, or disease diagnosis. These are the most widely used machine learning models for classification problems:
| Aspect | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data | Labeled | Unlabeled | Action-feedback loop |
| Goal | Predict outcomes | Discover hidden patterns/clusters | Maximize cumulative rewards |
| Examples | Spam detection, price prediction | Customer segmentation, anomaly detection | Game playing, self-driving, robotics |
| Algorithms | Linear Regression, SVM, Decision Trees | K-Means, PCA, Hierarchical Clustering | Q-Learning, SARSA, Deep Q-Networks |
| Feedback | Direct (with known output) | No direct feedback | Indirect via rewards/penalties |
| Training Process | One-time training with historical labeled data | Pattern discovery through data structure analysis | Continuous learning via exploration & exploitation |
| Computational Cost | Generally lower than RL | Moderate | High due to simulation or environment interaction |
| Applications | Email filtering, stock forecasting, diagnostics | Market segmentation, recommendation systems | Robotics, gaming AI, autonomous decision-making |
Avoid guesswork, choose models that deliver results. Future-proof your product with scalable intelligence.
Real-World Applications of ML Models with examples

From lane detection to pedestrian tracking, Machine Learning is at the heart of autonomous driving systems. These vehicles rely on a fusion of real-time data from cameras, LiDAR, GPS, and radar to make driving decisions that mimic, and often surpass human abilities.
Technical Details:
Autonomous vehicles utilize a stack of ML models to perform distinct yet interconnected tasks.
- Object Detection: YOLO (You Only Look Once) and Faster R-CNN are used to detect pedestrians, vehicles, traffic signs in real time from video frames.
- Semantic Segmentation: Deep networks like SegNet or DeepLab divide scenes into pixel-level categories (e.g., road, sidewalk, car).
- Sensor Fusion: ML algorithms fuse data from LiDAR and cameras to improve perception accuracy. Kalman Filters and Bayesian Networks enhance probabilistic decision-making.
- Path Planning: Reinforcement Learning models such as Deep Q-Networks (DQNs) help the vehicle learn to navigate roads, make lane changes, or stop at intersections based on reward-based learning.
Training involves large-scale simulation environments (like Carla or LGSVL) and real-world annotated driving datasets (e.g., KITTI, Waymo Open Dataset). The models are trained using stochastic gradient descent or Adam optimizers and evaluated on metrics like Mean Average Precision (mAP) for detection and Intersection-over-Union (IoU) for segmentation.
Real-World Examples:
- Tesla Autopilot: Uses an end-to-end deep learning approach combining vision-based perception and behavior prediction.
- Waymo: Alphabet’s self-driving car unit uses high-resolution LiDAR and deep neural networks for robust 360° perception and path planning.
From real-time fraud detection to algorithmic trading, machine learning is reshaping the financial landscape. AI-driven models empower institutions to analyze massive datasets, predict market movements, and automate risk assessments, all in milliseconds.
Technical Details:
Financial systems use a suite of specialized ML models tailored for high-frequency, high-stakes environments.
- Fraud Detection: Uses Isolation Forest, Autoencoders, and One-Class SVMs to detect anomalies in transactional data. Ensemble models like XGBoost help reduce false positives.
- Risk Scoring: Logistic Regression and Gradient Boosting Machines (GBMs) assess borrower creditworthiness based on financial history, income, and behavioral patterns.
- Algorithmic Trading: Deep Reinforcement Learning models like Deep Deterministic Policy Gradient (DDPG) and Proximal Policy Optimization (PPO) are used to learn optimal trading strategies under uncertain conditions.
- Forecasting: LSTM (Long Short-Term Memory) networks and ARIMA models are employed to predict stock prices, interest rates, or market volatility based on sequential financial data.
- Sentiment Analysis: NLP models like BERT and FinBERT extract market sentiment from financial news and social media, feeding into real-time decision pipelines.
Training utilizes time-series datasets (e.g., Bloomberg, Quandl) and transaction logs, with custom loss functions optimized for profit maximization or risk minimization.
Real-World Examples:
- JPMorgan Chase: COiN platform uses ML to analyze thousands of legal documents in seconds.
- Robinhood: Uses reinforcement learning to optimize user engagement and trade execution.
- PayPal: Implements deep learning for fraud detection and anomaly monitoring at scale.
In retail, AI is the invisible salesperson. From predicting inventory needs to personalizing the customer journey, machine learning is central to driving operational efficiency and customer satisfaction.
Technical Details:
Retailers deploy ML models across the supply chain, marketing, and in-store technologies.
Recommendation Engines: Collaborative Filtering, Neural Collaborative Filtering (NCF), and Matrix Factorization drive personalized suggestions on e-commerce platforms.
- Demand Forecasting: Regression Trees, Prophet, and DeepAR predict SKU-level sales based on seasonality, pricing, and promotions.
- Computer Vision for Visual Search: Convolutional Neural Networks (CNNs) and YOLO models allow customers to search products via images and detect shelf availability in smart stores.
- Dynamic Pricing: Reinforcement Learning models adjust prices in real time based on competitor data, demand trends, and customer behavior.
- Customer Segmentation: K-Means, DBSCAN, and Hierarchical Clustering help segment users by purchasing behavior, enabling hyper-targeted marketing campaigns.
Datasets include clickstreams, transaction logs, and product images. Training often involves real-time data pipelines and scalable ML architectures using Spark MLlib or TensorFlow Extended (TFX).
Real-World Examples:
- Amazon: Leverages real-time ML to personalize homepages, recommend products, and optimize logistics.
- Walmart: Uses predictive analytics for supply chain optimization and computer vision in smart fridges.
- Zalando: Employs AutoML for fashion tagging and outfit generation based on user preferences.
How to Choose the Best Machine Learning Development Services
Tech startups and SMEs need more than just code, they need strategic intelligence.
Here’s how to find the right machine learning partner:
- 1. Domain Expertise Select a team that understands your industry inside out, this ensures your ML models are aligned with real business needs.
- 2. Custom-Tailored Solutions Avoid one-size-fits-all approaches. Go with providers who build models that match your unique product, customer, and data landscape.
- 3. End-to-End Capabilities From data preparation and model training to deployment and scaling, the right partner handles the full ML lifecycle seamlessly.
- 4. Advanced Tech Stack Ensure proficiency in the latest ML frameworks (TensorFlow, PyTorch) and cloud platforms (AWS, Azure, GCP) for smooth, scalable integration.
- 5. Trusted by InnovatorsChoose a proven machine learning development company like Sunrise Technologies, trusted by fast-growing startups to deliver AI-driven success.
Machine Learning Models have redefined the boundaries of innovation and efficiency across industries. From supervised learning to unsupervised and reinforcement models, each approach offers unique strengths depending on the business challenge. Choosing the right model not only boosts prediction accuracy but also drives intelligent automation, making it essential for organizations to invest in best ML model development and AI-driven decision-making systems.
If you’re looking to unlock the full potential of AI, partnering with the top ML development company in the USA and Australia is the key. At Sunrise Technologies, we offer the best AI development services tailored to your industry needs, ensuring scalable, robust, and future-ready ML solutions. Let’s build the next-gen AI systems that transform your data into actionable intelligence.
Make sense of your business data with precision. We help startups deploy AI faster, smarter, and leaner.
Some of the best machine learning models for classification include Random Forest, SVM, and Naive Bayes due to their accuracy and adaptability.
Supervised learning uses labeled data, while unsupervised learning works with unlabeled data to find hidden patterns.
ML model development can range from $5,000 to $100,000+, depending on complexity, data size, and customization needs. You can achieve affordable ML development with the best ML development services like Sunrise Technologies.
Common real-world applications of ML models include fraud detection in finance, product recommendations in retail, and disease diagnosis in healthcare.
Consider your data type, output requirement (classification vs regression), and complexity of the problem when choosing the right machine learning model for your data.

Sam is a chartered professional engineer with over 15 years of extensive experience in the software technology space. Over the years, Sam has held the position of Chief Technology Consultant for tech companies both in Australia and abroad before establishing his own software consulting firm in Sydney, Australia. In his current role, he manages a large team of developers and engineers across Australia and internationally, dedicated to delivering the best in software technology.